

What Identifies Data Outside Of A Normal Condition?
5 Means to Detect Outliers/Anomalies That Every Data Scientist Should Know (Python Code)
Detecting Anomalies is critical to whatsoever business either past identifying faults or being proactive. This article discusses 5 different ways to identify those anomalies.
What is Bibelot/Outlier?
In statistics, outliers are information points that don't belong to a certain population. It is an abnormal observation that lies far away from other values. An outlier is an ascertainment that diverges from otherwise well-structured information.
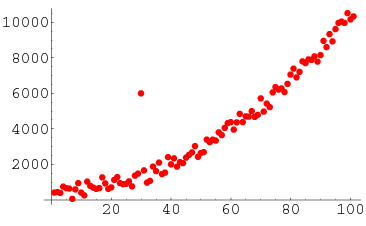
For Example, you can clearly see the outlier in this list: [20,24,22,19,29,eighteen,4300,thirty,xviii]
It is easy to identify it when the observations are only a bunch of numbers and it is one dimensional merely when y'all have thousands of observations or multi-dimensions, you will need more clever ways to notice those values. This is what this commodity will embrace.
Why Do We Intendance Most Anomalies?
Detecting outliers or anomalies is one of the core problems in data mining. The emerging expansion and connected growth of information and the spread of IoT devices, make us rethink the way we approach anomalies and the use cases that can be built by looking at those anomalies.
We now accept smart watches and wristbands that can discover our heartbeats every few minutes. Detecting anomalies in the heartbeat data can help in predicting heart diseases. Anomalies in traffic patterns tin can help in predicting accidents. Information technology can also exist used to identify bottlenecks in network infrastructure and traffic between servers. Hence, the use cases and solution congenital on top of detecting anomalies are limitless.
Another reason why we need to detect anomalies is that when preparing datasets for machine learning models, it is really of import to discover all the outliers and either get rid of them or analyze them to know why yous had them there in the first identify.
Now, let's explore 5 mutual ways to detect anomalies starting with the most simple fashion.
Method 1 — Standard Deviation:
In statistics, If a data distribution is approximately normal then about 68% of the data values lie within i standard divergence of the mean and about 95% are inside two standard deviations, and nearly 99.7% prevarication within three standard deviations
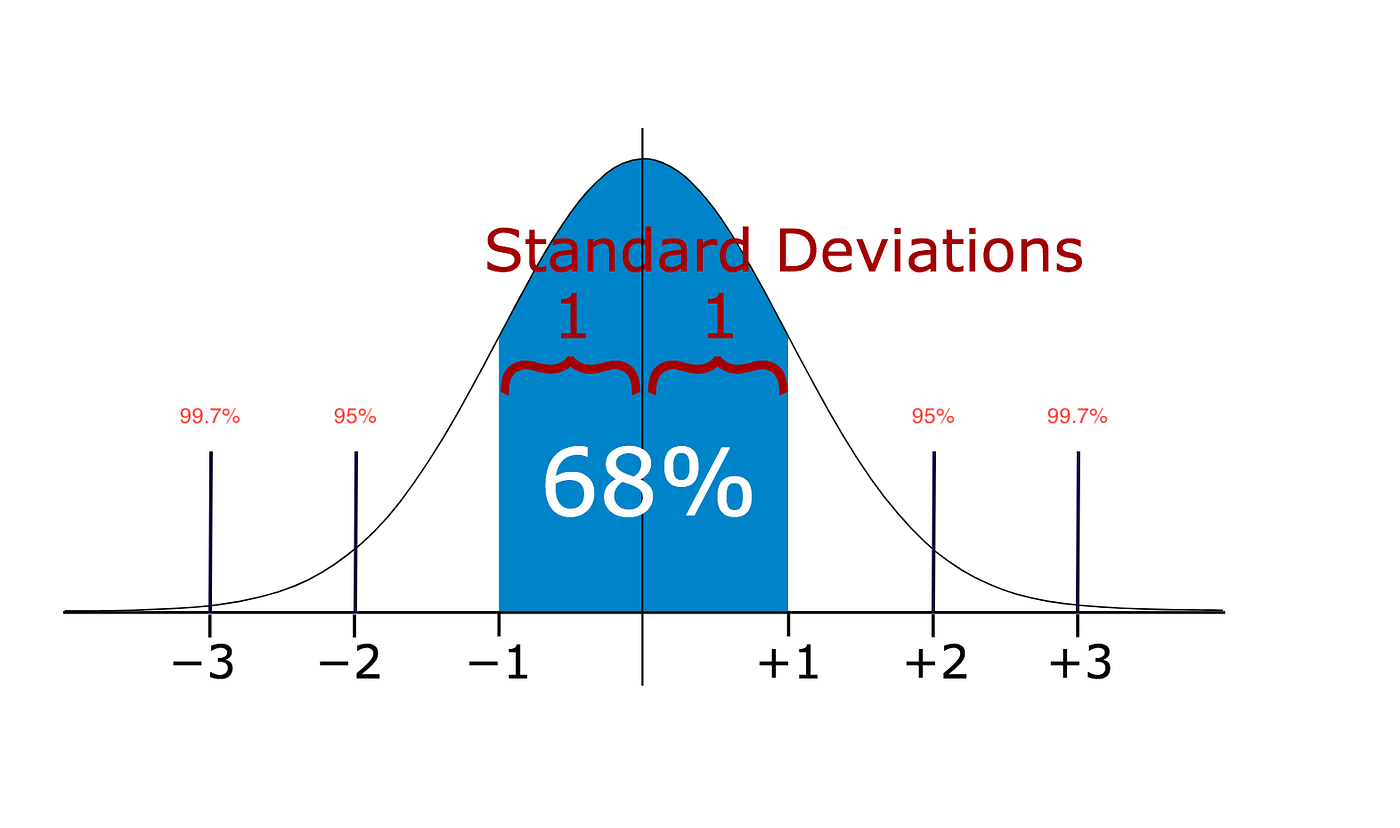
Therefore, if yous have any data point that is more than 3 times the standard deviation, and so those points are very likely to be anomalous or outliers.
Permit'due south run across some code.
The output of this lawmaking is a list of values in a higher place eighty and below -40. Notice that the dataset I am passing is a ane-dimensional dataset. At present, let's explore more advanced methods for multi-dimensional datasets.
Method 2 — Boxplots
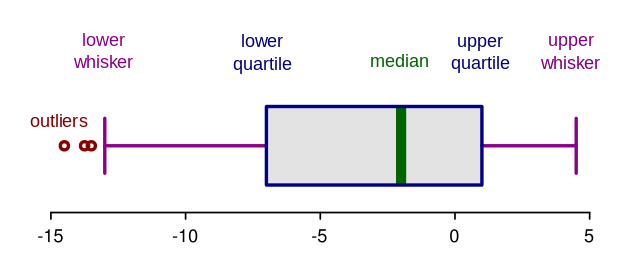
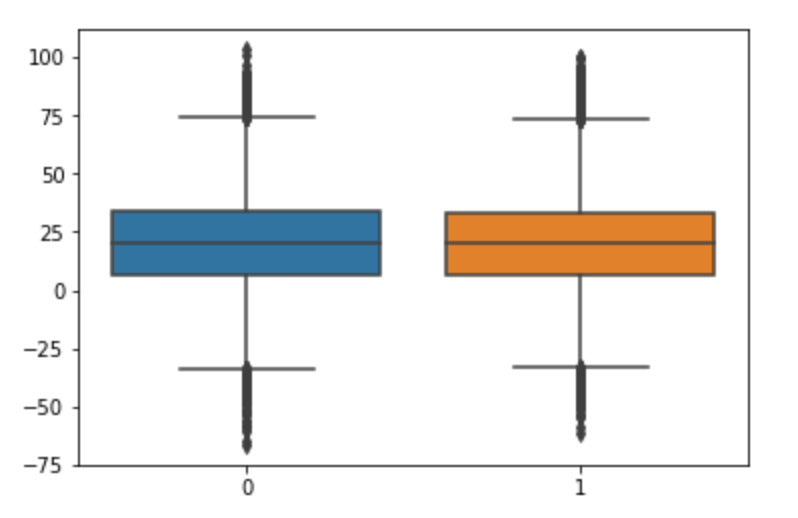
Box plots are a graphical delineation of numerical information through their quantiles. It is a very uncomplicated but effective manner to visualize outliers. Think about the lower and upper whiskers as the boundaries of the data distribution. Any information points that show in a higher place or below the whiskers, can exist considered outliers or anomalous. Here is the code to plot a box plot:
The higher up lawmaking displays the plot below. Equally yous can come across, it considers everything above 75 or below ~ -35 to be an outlier. The results are very shut to method one higher up.
Boxplot Beefcake:
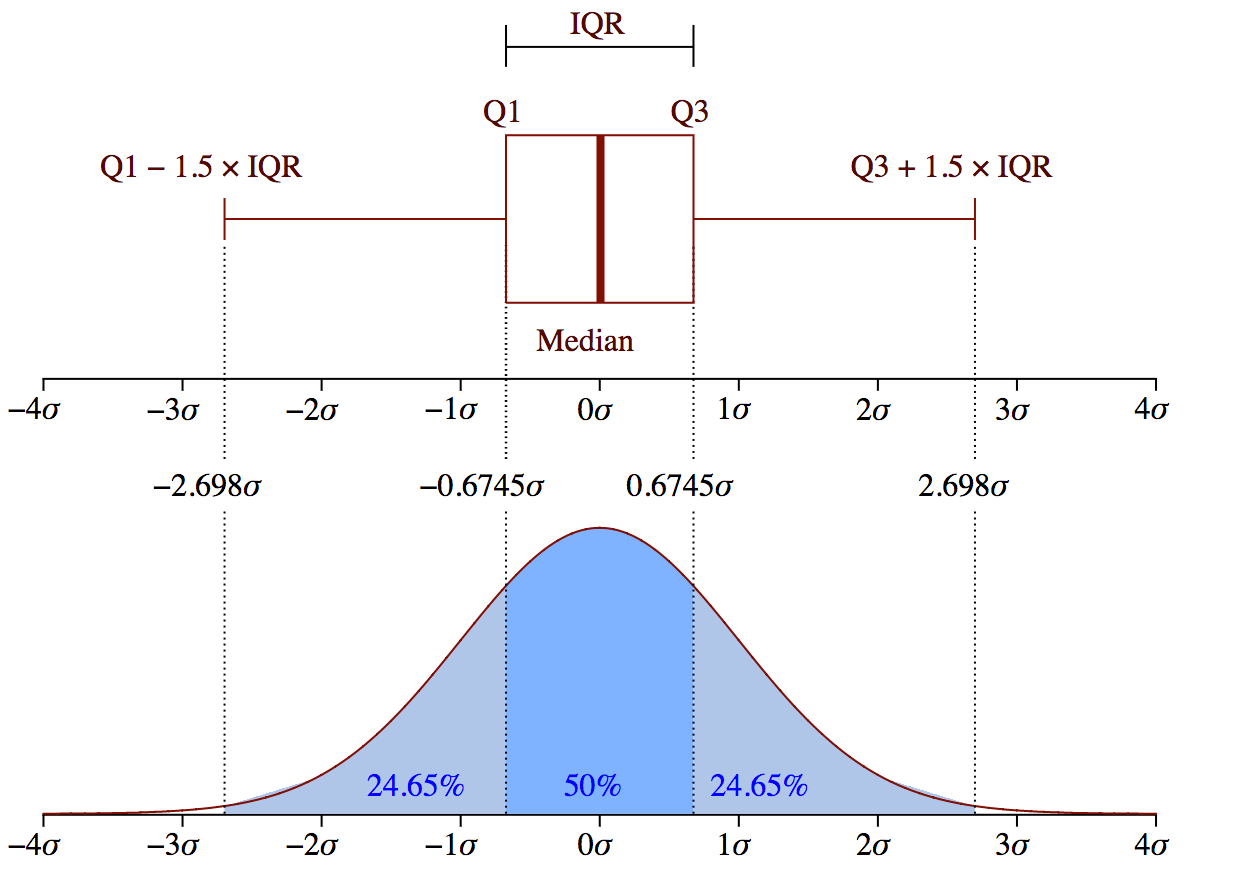
The concept of the Interquartile Range (IQR) is used to build the boxplot graphs. IQR is a concept in statistics that is used to measure the statistical dispersion and data variability past dividing the dataset into quartiles.
In uncomplicated words, whatsoever dataset or any set of observations is divided into 4 divers intervals based upon the values of the information and how they compare to the entire dataset. A quartile is what divides the data into three points and iv intervals.
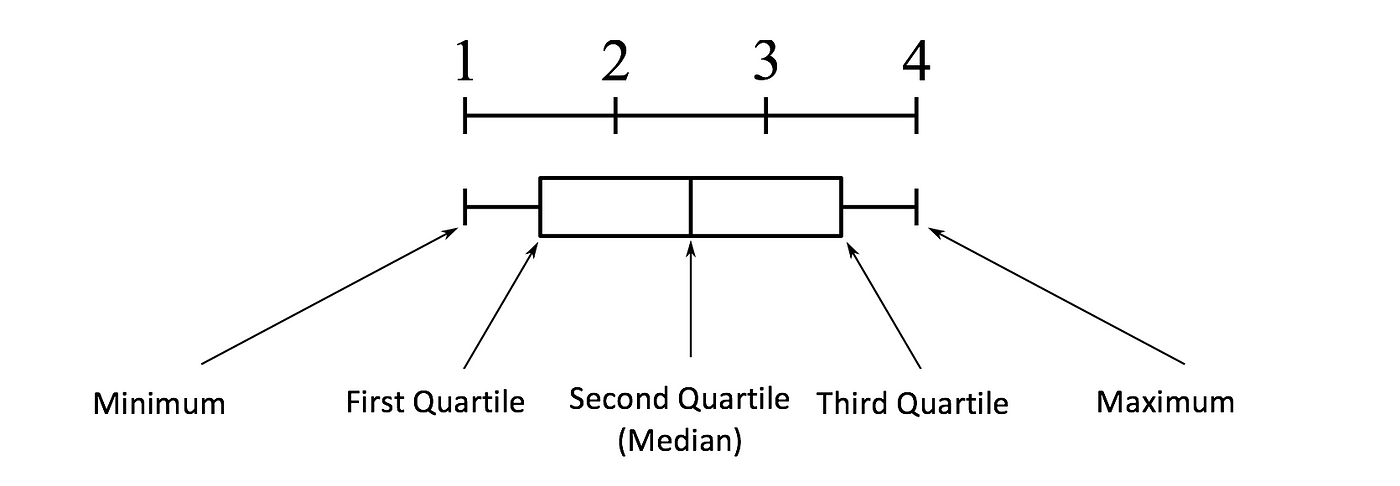
Interquartile Range (IQR) is important considering information technology is used to define the outliers. Information technology is the difference between the third quartile and the first quartile (IQR = Q3 -Q1). Outliers in this case are divers as the observations that are below (Q1 − 1.5x IQR) or boxplot lower whisker or above (Q3 + i.5x IQR) or boxplot upper whisker.
Method iii— DBScan Clustering:
DBScan is a clustering algorithm that'south used cluster data into groups. It is as well used as a density-based anomaly detection method with either unmarried or multi-dimensional data. Other clustering algorithms such as grand-means and hierarchal clustering can too exist used to detect outliers. In this case, I volition show you an example of using DBScan merely before nosotros start, permit's embrace some of import concepts. DBScan has three important concepts:
- Core Points: In social club to understand the concept of the core points, nosotros need to visit some of the hyperparameters used to define DBScan job. First hyperparameter (HP)is min_samples. This is but the minimum number of core points needed in order to form a cluster. 2nd important HP is eps. eps is the maximum distance between two samples for them to be considered as in the same cluster.
- Edge Points are in the aforementioned cluster as cadre points but much further away from the centre of the cluster.
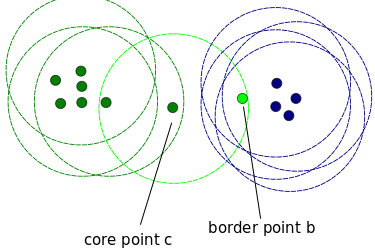
- Everything else is called Racket Points , those are data points that do not vest to any cluster. They can be anomalous or non-anomalous and they need farther investigation. At present, let's encounter some lawmaking.
The output of the in a higher place code is 94. This is the full number of noisy points. SKLearn labels the noisy points equally (-1). The downside with this method is that the higher the dimension, the less accurate it becomes. You also need to make a few assumptions similar estimating the right value for eps westwardhich tin be challenging.
Method 4— Isolation Forest:
Isolation Forest is an unsupervised learning algorithm that belongs to the ensemble conclusion trees family unit. This approach is unlike from all previous methods. All the previous ones were trying to find the normal region of the data then identifies annihilation exterior of this defined region to exist an outlier or anomalous.
This method works differently. It explicitly isolates anomalies instead of profiling and amalgam normal points and regions by assigning a score to each data bespeak. It takes advantage of the fact that anomalies are the minority information points and that they have attribute-values that are very different from those of normal instances. This algorithm works great with very high dimensional datasets and it proved to be a very effective fashion of detecting anomalies. Since this article is focusing on the implementation rather than the know-how, I will not go any further on how the algorithm works. Withal, the total details on how information technology works are covered in this newspaper.
At present, let's explore the lawmaking:
This code will output the predictions for each information point in an array. If the outcome is -1, it means that this specific information indicate is an outlier. If the event is ane, and then information technology means that the information point is not an outlier
Method 5— Robust Random Cutting Forest:
Random Cut Forest (RCF) algorithm is Amazon'southward unsupervised algorithm for detecting anomalies. Information technology works by associating an anomaly score too. Low score values indicate that the data point is considered "normal." High values point the presence of an anomaly in the data. The definitions of "low" and "high" depend on the awarding simply common practise suggests that scores across three standard deviations from the hateful score are considered dissonant. The details of the algorithm tin be found in this paper.
The bang-up affair well-nigh this algorithm is that information technology works with very high dimensional data. It can too work on existent-time streaming data (built in AWS Kinesis Analytics) as well as offline data.
I explain the concept in much more details in the video below:
The paper shows some performance benchmarks when compared with Isolation Forest. Here are the results from the paper which shows that RCF is much more authentic and faster than Isolation Forests.
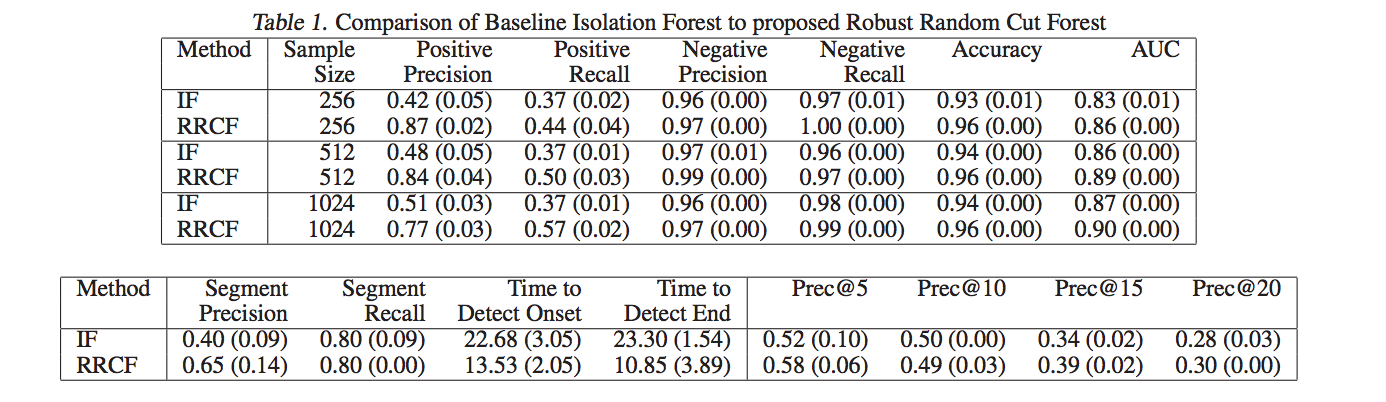
Full example code tin can be found here:
Conclusion:
We live in a world where the data is getting bigger by the second. The value of the data tin diminish over fourth dimension if not used properly. Finding anomalies either online in a stream or offline in a dataset is crucial to identifying issues in the business organization or building a proactive solution to potentially notice the problem earlier it happens or even in the exploratory data analysis (EDA) phase to prepare a dataset for ML. I hope that you find the article useful, let me know what y'all think in the comments section below.

What Identifies Data Outside Of A Normal Condition?,
Source: https://towardsdatascience.com/5-ways-to-detect-outliers-that-every-data-scientist-should-know-python-code-70a54335a623
Posted by: nelsonenterhad.blogspot.com
0 Response to "What Identifies Data Outside Of A Normal Condition?"
Post a Comment